
Sequence_Models
Published:
现实中很多数据其实都有时序结构的
比如预测股价(根据近几年的股价信息),文本的理解(文本和上下文有关系,计算机要理解文本的文字就得结合上下文的信息)……故音乐、语言、文本和视频都是连续的
序列模型
前置知识
条件概率
\[p(a,b)=p(a)p(b|a)=p(b)p(a|b)\]| 条件概率表示为$P(A | B)$,读作“A在B发生的条件下发生的概率” |
联合概率表示两个事件共同发生的概率。A与B的联合概率表示为$P(A,B)$或者$P(AB)$
些许统计工具
在时间 $t$ 观察到 $x_t$ ,那么得到 $T$ 个不独立的随机变量 $(x_1,…,x_T)\sim p(x)$
\[p(X)=p(x_1) \cdot p(x_2|x_1)\cdot p(x_3|x_1,x_2)\cdot p(x_T|x_1,...,x_{T-1})\]| 其中$p(x_3 | x_1,x_2)$ 为在$x_1,x_2$条件下发生 $x_3$ 的概率 |
模型建立

对条件概率建模
\[p(x_t|x_1,...,x_{t-1})=p(x_t|f(x_1,...,x_{t-1}))\]马尔可夫假设
假设当前数据只和过去 $\tau$ 个数据点有关(不然数据量大的话,每一个点都和前面所有点有关联计算量过于庞大,有时候实际情况也是并不一定和很久之前的信息点有关系)
\[p(x_t|x_1,...,x_{t-1})=p(x_t|x_{t-\tau},...,x_{t-1})=p(x_t|f(x_{t-\tau},...,x_{t-1}))\]潜变量模型
引入潜变量 $h_t$ 来表示过去信息 $h_t=f(x_1,…,x_{t-1})$
| 这样 $x_t=p(x_t | h_t)$ |
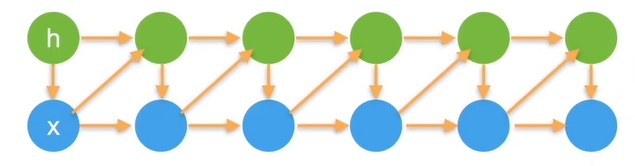
每一个旧的 $x_{t-1}$ 和 $h_{t-1}$ 都会合成一个新的 $h_t$ ,然后旧的 $x_{t-1}$ 和新合成的 $h_t$ 共同合成新的 $x_t$ ,如图所示
PS:感觉很像动态规划,极大减小了计算量