

ML/DeepLearning Note2-MLP(多层感知机)
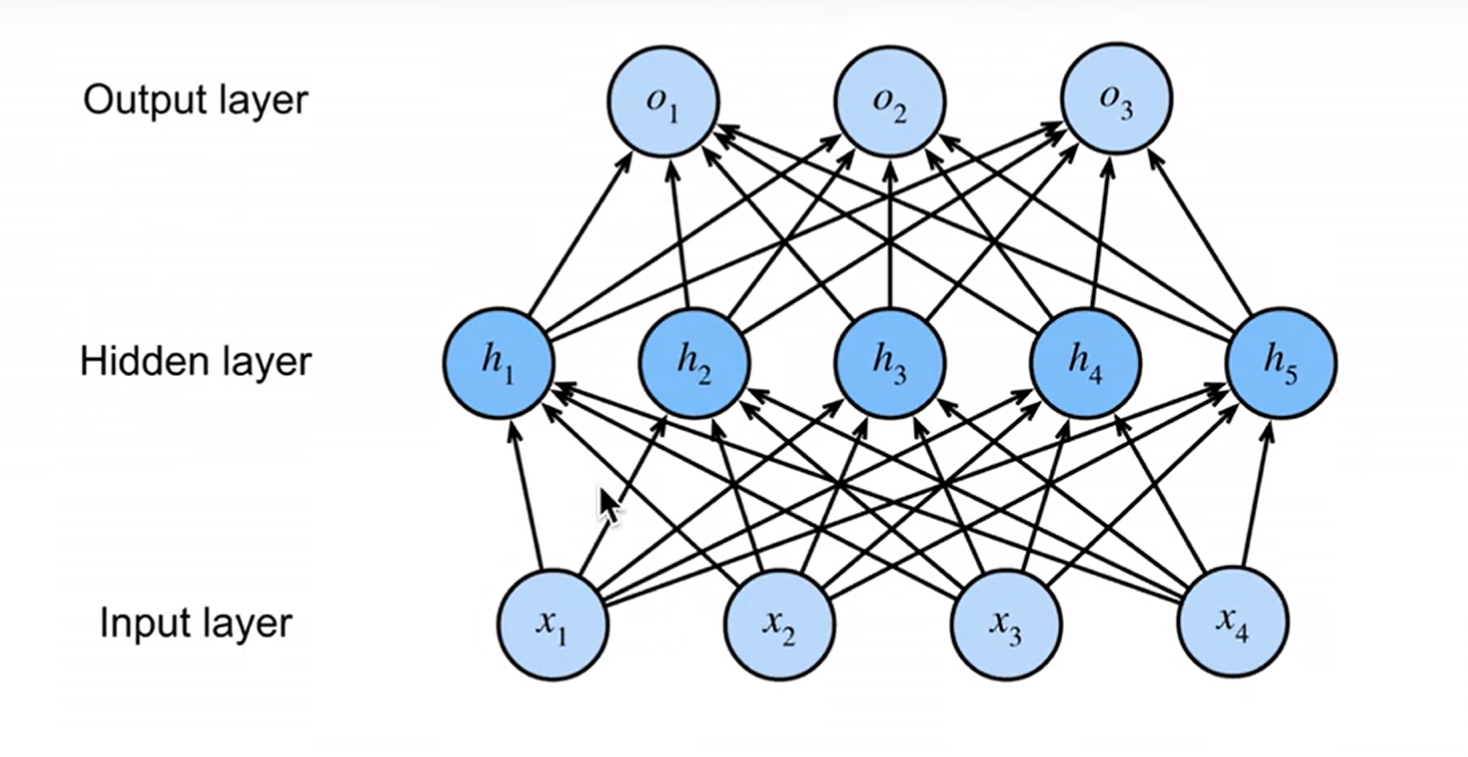
tips:一般在神经网络中,一层神经网络指的是权重
多层感知机的实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import torch
from torch import nn, softmax
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs , num_outputs, num_hiddens = 784,10,256
#第一层是输入层
W1 = nn.Parameter(torch.randn(num_inputs,num_hiddens,requires_grad=True))
#前面两个参数分别对应行数和列数
b1 = nn.Parameter(torch.zeros(num_hiddens,requires_grad=True))
#第二层是输出层
W2 = nn.Parameter(torch.randn(num_hiddens,num_outputs,requires_grad=True))
b2 = nn.Parameter(torch.zeros(num_outputs,requires_grad=True))
params = [W1,b1,W2,b2]
def relu(X):
a = torch.zeros_like(X)
#生成一个全0的tensor,和X的形状一致
return torch.max(X,a)
#模型实现
def net(X):
X = X.reshape((-1,num_inputs))
H = relu(torch.matmul(X,W1) + b1)
return torch.matmul(H,W2) + b2
loss = nn.CrossEntropyLoss()
#模型的训练
num_epochs , lr = 10, 0.1
updater = torch.optim.SGD(params,lr=lr)
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,updater)
ML/Deep Learning Note1-杂记
机器学习的一点笔记(其实只是拿来练一下公式输入)
1、sigmoid activation function
2、RELU activation function