
GAN笔记
Published:
两个核心
Generator
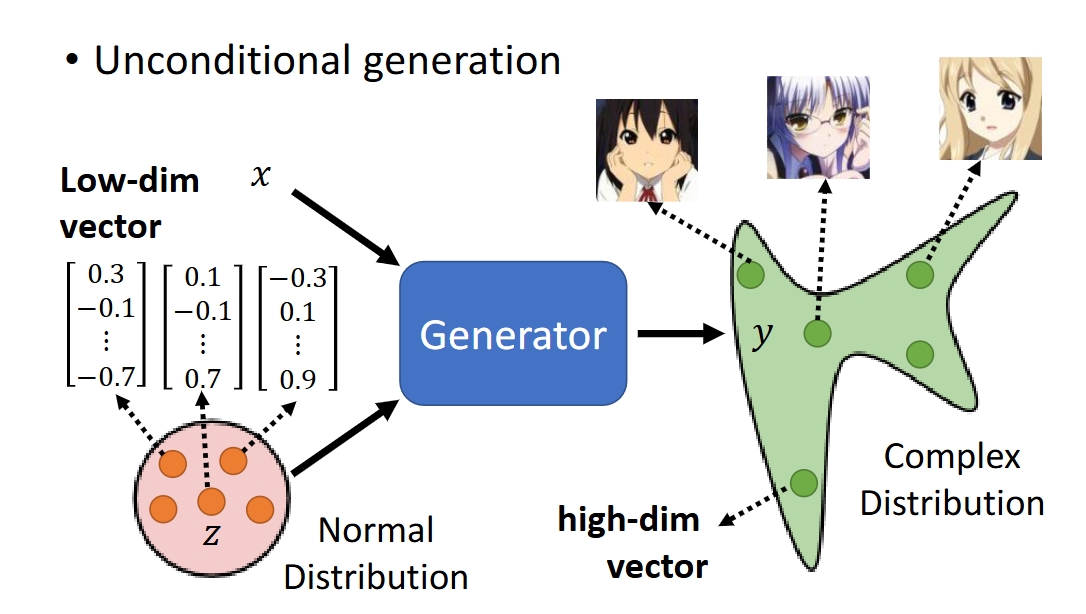
作用:通过CNN等神经网络从Normal Distribution中拿出很多低维向量生成遵循一个复杂的分布的很多高维向量(实际应用中多用于图片的生成,目标是要骗过Discriminator的辨别,骗它这张假的生成的图片是真实的图片)
Discriminator
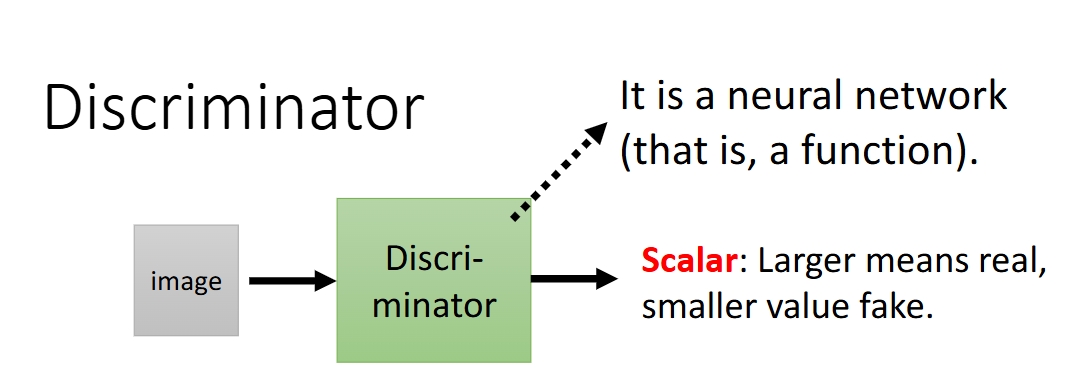
作用:辨别从Generator那边产生的图片,努力辨别图片真假与否
输入是一张图片,输出是一个标量,越大意味着图片越真实,越小意味着图片越假
例如:

所以,GAN就是Generator和Discriminator的博弈,最后训练出可以产生以假乱真的Generator
优化函数的目标函数
GAN(生成式对抗神经网络)要如何不断优化Generator和Discriminator呢?使得Generator生成图片的能力越来越强,Discriminator辨别的能力也越来越强
Generator这边
前人已经探索出来,求出具体的分布函数是不大可能的,太复杂,太难计算,发现从真实数据集和生成数据集中采样(Sampling)后,对比他们的差异(用交叉熵,KL散度,JS散度等等),就可以达到非常不错的效果,故:
\[G^*=arg\min_GDiv(P_G,P_{data})\]Div指的是求从两个数据集采样得到的数据的分布的散度。
从公式中,我们也可以看出,Generator要努力让生成的数据和真实数据之间的差异越小越好。
Discriminator这边
直接看公式:
\[D^*=arg\max_DV(D,G)\]Objective Funciton for D \(V(G,D)=E_{y\sim P_{data}}[logD(y)]+E_{y\sim P_{G}}[log(1-D(y))]\)
回到刚刚Discriminator的目标,它致力于把一张真实的图片打分打得越高越好,而虚假的图片(Generator产生的)则尽可能地分数低一些。
所以公式上面从真实数据集$P_data$中获取得到的$D(y)$要尽可能的大,而从生成数据集中获取的$D(y)$要尽可能的小
这个Objective Function其实就是交叉熵方程乘一个负号(negative cross entropy) 而我们要最大化$D^*$,实际上就是最小化两个数据集的交叉熵,这也与我们的目标是一致的,Discriminator就是要使两个数据集越来越远,能够区分真实数据与生成的虚假数据。通过最小化交叉熵,我们鼓励判别器提高其对真实数据的识别能力,同时降低对生成数据的误判。
$\max_D V(D,G)$ is related to JS divergence
Discriminator and Generator
现在我们回看Generator的公式 \(G^*=arg\min_GDiv(P_G,P_{data})\) 我们要求解G,需要知道$P_G$和$P_{data}$的Divengence,但是很难求解。我们刚刚又提到,$\max_DV(D,G)$实际就是求解交叉熵,可以间接得到Divergence,所以不妨用$\max_DV(D,G)$替换$Div(P_G,P_{data})$得到最后的公式
\[G^*=arg\min_G\max_DV(G,D)\]