
DiffusionModel
Published:
INTRODUCTION
Divided into part procession , Diffusion Model has a “Forward Process” and a “Reverse Process”.
Forward Process
Continuously adding noise into a image

Reverse Process
Continuously denoise the image that filled with noise by training a neural network

Objective
Then we could use the trained network to produce a new picture from a random noise-distribution image
VAE vs. Diffusion Model
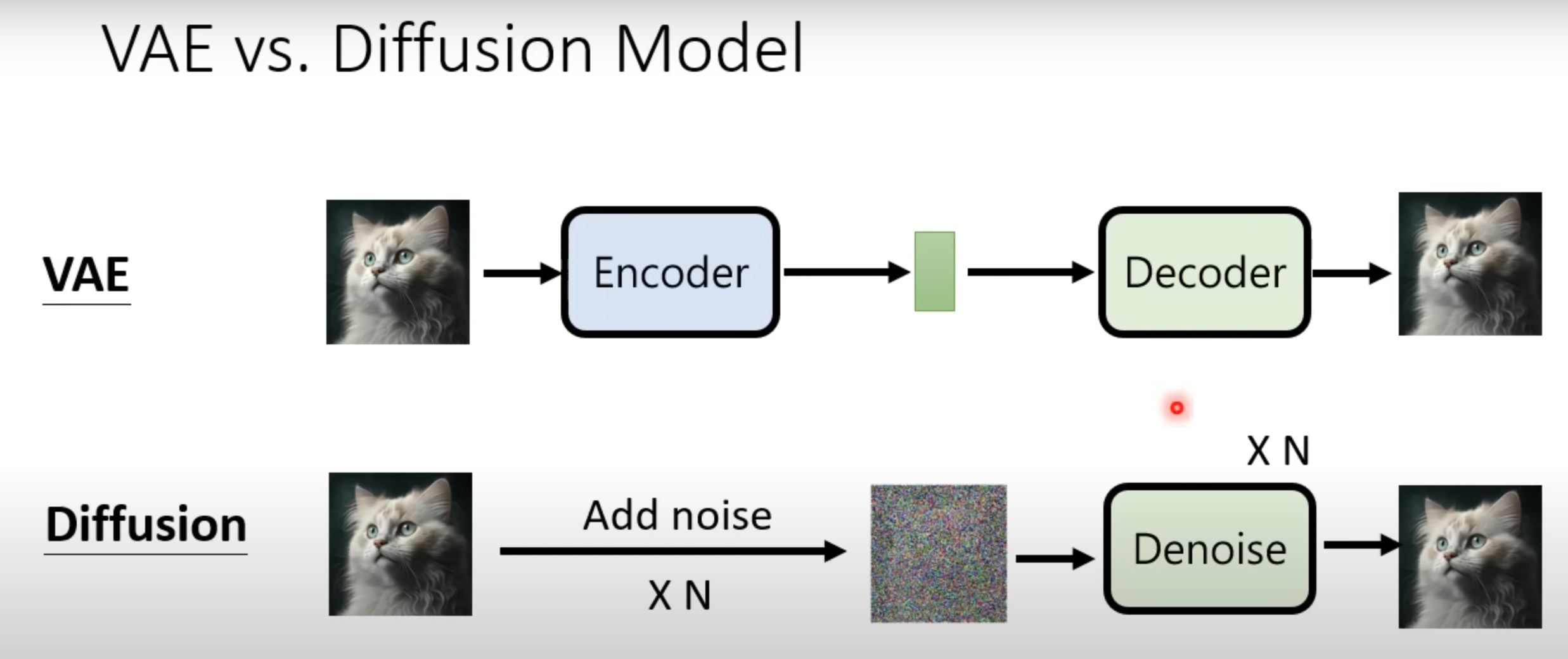
The bottleneck part or the CODE in the VAE model is quite like the picture after adding noise N times
Training Algorithm
$Algorithm$
$1:repeat$
$2:x_0\sim q(x_0)$
$3:t\sim Uniform(1,…,T)$
$4:\epsilon\sim N(0,1)$
$5:$ Take gradient descent step on
| $\nabla_\theta | \epsilon-\epsilon_\theta(\sqrt{\bar{\alpha_t}}x_0+\sqrt{1-\bar{\alpha_t}}\epsilon,t) | ^2$ |
$6:$until converged
In Diffusion Model
$x_0$ means “sample a clean image”
$\epsilon\sim N(0,1)$ means “sample a noise”,which is Target Noise
$\epsilon_\theta(X,t)$ is a Noise predictor function which mix clean image and noisy images together with specific weights($\sqrt{\bar{\alpha_t}}$ and $\sqrt{1-\bar{\alpha_t}}$)
tips:$\bar{\alpha_1},\bar{\alpha_2},\bar{\alpha_3},\bar{\alpha_4},\bar{\alpha_5},…,\bar{\alpha_T}$ is increasingly smaller ,which means the noise will Noise takes up a larger percentage of the image
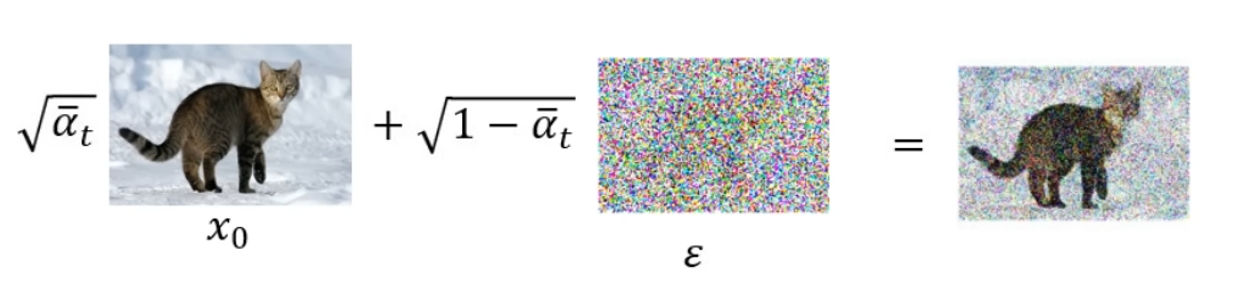
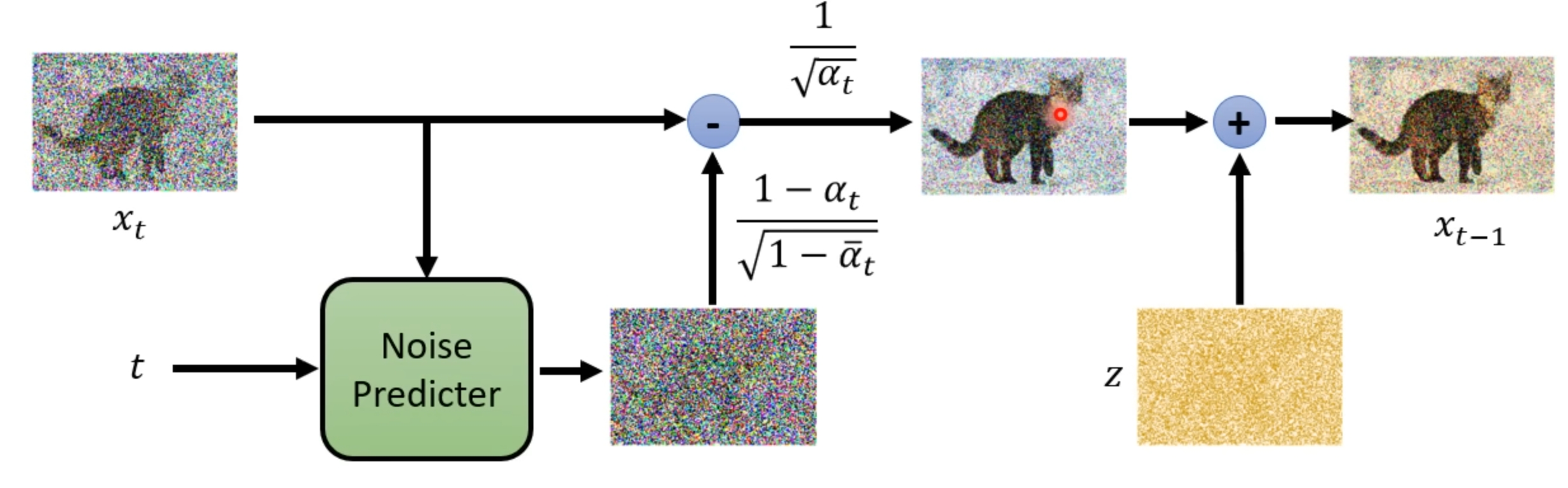
Sampling
Algorithm
$1:x_T\sim N(0,1)$
$2:for$ $t=T,…,1$ do
$3:z\sim N(0,1)$ if $t>1$ else $z=0$
$4:x_{t-1}=\frac{1}{\sqrt{\alpha_t}}(x_t -\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha_t}}}\epsilon_\theta(x_t,t))+\sigma_tz$
$5:$ end for
$6:$ return $x_0$
Maximum Likelihood Estimation
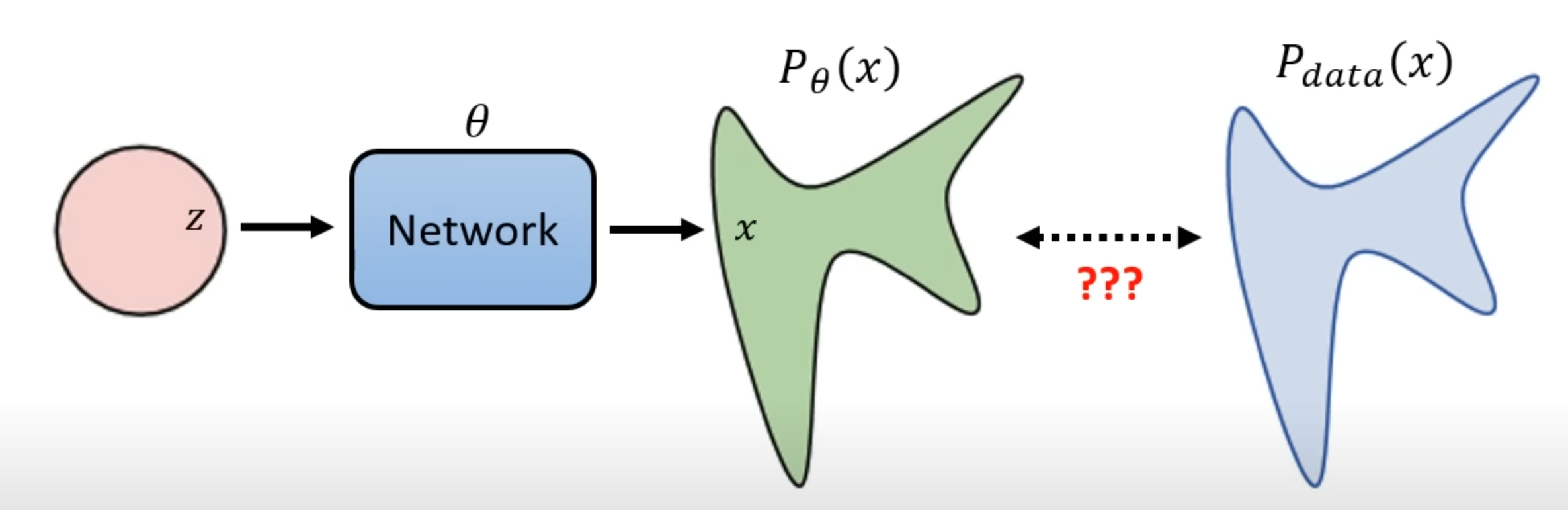
we sample {$x^1,x^2,…,x^m$} from $P_{data}(x)$
So how we can compute the $P_\theta(x^i)$ because the distribution is so complicated that we can’t work out the objective function easily
We want to find a $\theta$ that can maximum the Likelihood Estimation
\[\theta^*=arg\max_\theta\prod_{i=1}^mP_\theta(x^i)\] \[\begin{equation}\begin{split} \theta^*&=arg\max_\theta\prod_{i=1}^mP_\theta(x^i)\\\\&=arg\max_\theta log\prod_{i=1}^mP_\theta(x^i)\\\\&=arg\max_\theta \sum_{i=1}^mlogP_\theta(x^i)\\\\&\approx arg\max_\theta E_{x\sim P_{data}}[logP_\theta(x^i)]\\\\ &=arg\max_\theta( \int_xP_{data}(x)logP_\theta(x)dx - \int_xP_{data}(x)logP_{data}(x)dx) \\\\ &=arg\max_\theta \int_xP_{data}(x)log\frac{P_\theta(x)}{P_{data}(x)}dx\\\\&=arg\min_\theta KL(P_{data}||P_\theta)\end{split}\end{equation}\]So maximum likelihood estimation is to minimum the KL divergence(like VAE)
By the way,$\int_xP_{data}(x)logP_{data}(x)dx$ is not related to $\theta$ , so we could add it freely