Batch Normalization(BN-批量归一化)
为什么要提出BN
在训练神经网络的时候,前面层的网络往往数据规模比较大,越往后的网络规模会越来越小(因为最后总要输出某些东西,比如1-10的预测值),故在训练神经网络的过程中,存在以下问题:
底部的层训练较慢
底部层一变化,所有东西都得更着一起变,导致顶部的层又得重新训练一次,导致收敛变慢
下图是VGG网络(可以看出网络是经典的逐渐收敛的形状
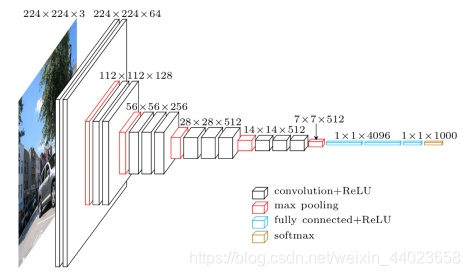
所以,我们可以在学习底部层的时候避免变化顶部层吗?
Batch Normalization
固定小批量里面的均值和方差
and
然后再做额外的调整(同时引入两个可以学习的参数
Batch Normalization Layer(批量归一化层)
可以学习的参数为
作用在
全连接层和卷积层的输出上,激活函数前
全连接层和卷积层的输入上
对于全连接层,作用在特征维
对于卷积层,作用在通道维
总结
批量归一化固定小批量中的均值和方差,然后学习出合适的偏移和缩放(
可以加速收敛速度,但一般不改变模型精度1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26def batch_norm(X,gamma,beta,moving_mean,moving_var,eps,momentum):
#is_grad_enabled()判断是否是训练模式or 预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2,4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。这里我们需要保持
# X的形状以便后面可以做广播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# 训练模式下,用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y,moving_mean.data,moving_var.data1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class BatchNorm(nn.Module):
def __init__(self,num_features,num_dims):
super().__init__()
if num_dims == 2:
shape = (1,num_features)
else:
shape = (1,num_features,1,1)
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self,X):
# 如果X不在内存上,将moving_mean和moving_var复制到X所在显存上
if self.moving_mean.device != X.device:
#设备一致性检查:if self.moving_mean.device != X.device: 确保移动平均的均值和
# 方差与输入数据X在同一个设备上(CPU或GPU)
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y,moving_mean,moving_var = batch_norm(X,self.gamma,self.beta,self.moving_mean,self.moving_var,eps=1e-5,momentum=0.9)
return Y